Jumpstart your AI Journey: NVIDIA L40S GPUs with Supermicro
Experience an end-to-end AI and HPC data center platform with Supermicro systems and L40S GPUs


Unparalleled AI and Graphics Performance for the Data Center
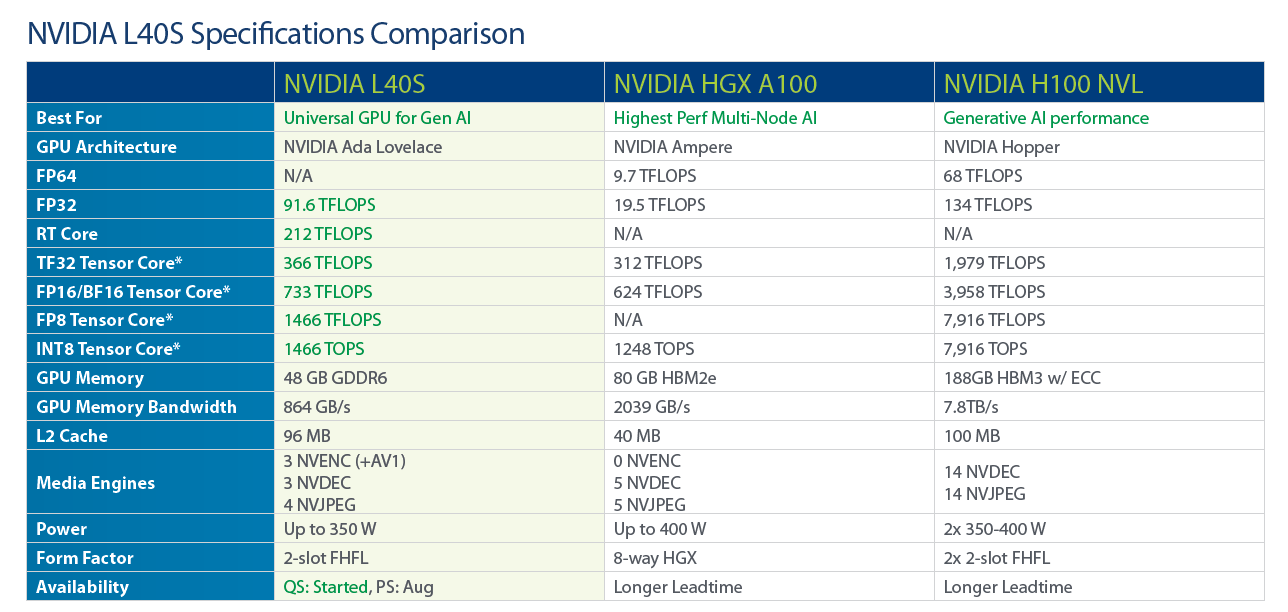
The NVIDIA L40S GPU, based on the Ada Lovelace architecture, is the most powerful universal GPU for the data center, delivering breakthrough multi-workload acceleration for large language model (LLM) inference and training, graphics, and video applications.
 |
 |
 |
 |
|
Generative AI The AI, graphics, and media acceleration capabilities of the L40S GPU make it the premier platform for multi-modal generative AI pipelines. |
LLM Inference and Training Accelerate training, fine tuning, and inference workloads with powerful throughput and floating-point performance to build and deploy state-of-the-art AI models. |
Rendering and 3D Graphics Running professional 3D visualization applications with NVIDIA L40S enables creative professionals to iterate more, render faster, and unlock tremendous performance advantages that increase productivity and speed up project completion. |
Streaming and Video Content The NVIDIA L40S takes streaming and video content workloads to the next level, delivering breakthrough media acceleration capabilities with three video encode and three video decode engines. |
Try Before You Buy
Test drive Supermicro systems with L40S GPUs to experience unparalleled graphics and breakthrough multi-workload acceleration for large language model (LLM) inference and training, graphics, and video applications
Accelerate Everything

Supermicro Systems with the latest NVIDIA L40S GPU, offer ample supply and drive breakthroughs in multi-workload acceleration for large language model (LLM) inference and training, graphics, and video applications. As the premier platform for multi-modal generative AI, Supermicro solutions with L40S GPUs, provide end-to-end acceleration for inference, training, graphics, and video workflows to power the next generation of AI-enabled audio, speech, 2D, video, and 3D applications.
Introducing NVIDIA L40S GPU

Part Number: GPU-NVL40S
- The new Ada Lovelace Architecture features new Streaming Multiprocessor, 4th-Gen Tensor Cores, 3rd-Gen RT Cores, and 91.6 teraFLOPS FP32 performance.
- Experience the power of Generative AI, LLM Training, and Inference with features like Transformer Engine - FP8, over 1.5 petaFLOPS Tensor Performance*, and a Large L2 Cache.
- Unleash unparalleled 3D Graphics & Rendering capabilities with 212 teraFLOPS RT Core Performance, DLSS 3.0 for AI Frame Generation, and Shader Execution Reordering.
- Enhance Media Acceleration with 3 Encode & Decode Engines, 4 JPEG Decoders, and AV1 Encode & Decode Support.